Re-arhitecture a Fleet Tracking System
CLIENT
Mobile Provider
SERVICES
Web Development
TECHNOLOGIES
- .NET
- SQL Server
- RabbitMQ
- Redis
- ElasticSearch
- Azure DevOps
- Docker
Case studies
Other usecasesDescription
A major telecom company built a GPS tracking system for fleet management. It connects to vehicle computers to collect important data like mileage and speed, then sends this information over the network. However, their old system had serious limitations that were blocking business growth.
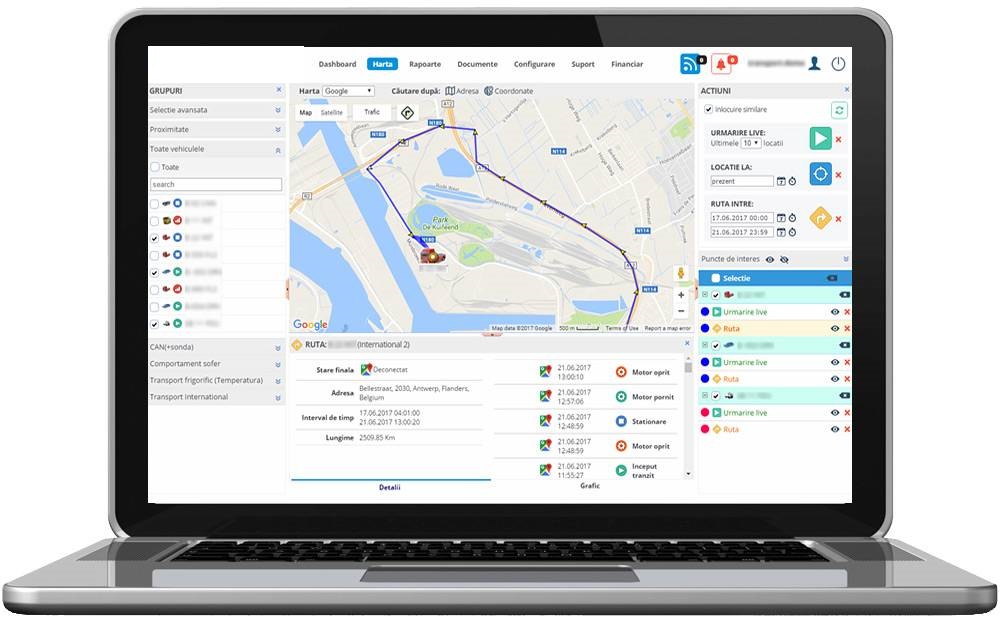

Key Achievements:
- Performance Improvement - We achieve 8,000 concurent harware connected on a single server under simulated load. Compared with the previous version, we gained a 5x improvement in speed and message handling
- System Reliability - Reduced errors to just 0.009% over the spawed of 3 days
- Production Success - Launched after 2 years of failed attempts
Original context
The original system was built years ago and had become difficult to maintain. The legacy monolithic application had accumulated significant technical debt over time, creating several critical business constraints:
- Growth: The system couldn’t handle new clients, which directly limited how much money the company could make
- Maintenance: Years of accumulated technical debt made the system difficult to maintain and extend
- Scalability: Performance degraded significantly under load
- Code Complexity: The system had become hard to follow and understand from code and monitoring
The rewriting problems
An outside company was hired to rebuild the system using modern microservices architecture. The initiative aimed to improve accuracy and overcome the legacy limitations. It also added some new features like supporting 100 binary protocols (more hardware devices) and failover capabilities.
After 2 years of development resulted a solution with 4 microservices and substantial investment, the project failed to be in production. With the huge amount of messages sent over the message bus, it was extremely difficult to monitor.

Problems Created by the Rewrite:
- Hard to debug: Having tasks split in 4 microservices was extremely difficult to monitor
- State management: The architecture introduced new security risks and made difficult to manage state over all microservices
- Monitoring Chaos: The system generated excessive logging and was dificult to monitor. Many things were already present like distributed traces, but because of the amoung of errors - making issue identification nearly impossible
- Performance Problems: System response times were unacceptable for production use
With over 2300 unit tests delivered, quality was not an issue including a good coverage. On paper everything looked great, but in production things looked differently.
After 2 years and lots of money spent, the new system still couldn’t go live. It had performance issues and too many bugs. This frustrated the business and went way over budget.
Investigation & Discovery
When I joined the project, the system was handling so many messages in the message bus, that finding bugs was like looking for a needle in a haystack. My first step was to gather as much data about existing issues and understand the context, so:
- Message Dumping: Collected sample RAW input messages from the hardware devices with the purpose to have predictable outcomes
- End-to-End Testing: Wrote comprehensive tests that showed exactly what the output should be for any given input
- Reproducible Scenarios: This allowed us to create benchmark scenarios we could test repeatedly
Soon after implementing these tests, we discovered something critical that changed our entire approach:

We found that 50% of processing time was spent on services talking to each other and updating caches. This was pure waste - no real work was getting done.
This discovery revealed that the microservices architecture was creating more problems than it solved. The overhead of inter-service communication was consuming half of our processing power.
Solution Approach
We had to balance errors encountered in the logs, with the findings from the arhitecture. We implemented end-to-end tests to have a starting benchmark.
- Keep What Works: We maintained much of the original code since the existing code quality was sufficient to build upon
- Focus on Communication: Instead of rewriting everything, we focused on optimizing how services communicate
- Comprehensive Testing: Beyond the end-to-end tests, we built extensive test coverage to ensure reliability
- Gradual Simplification: We systematically removed unnecessary complexity while preserving functionality
We simplified the architecture by reducing unnecessary microservices, and achieved cutting 40% of the component complexity. There was also newer developments happening after, like built a failover mechanism that prevents GPS data from being lost if one of the component fails (Messaging bus, database).
The architectural changes were fundamental to our success:

Key Changes Made:
- Consolidated Communication: Reduced inter-service communication overhead
- Optimized Data Flow: Streamlined how data moves through the system
- Simplified Service Structure: Removed redundant microservices
- Enhanced Reliability: Added failover mechanisms for critical components
The transformation yielded remarkable improvements across all system metrics:
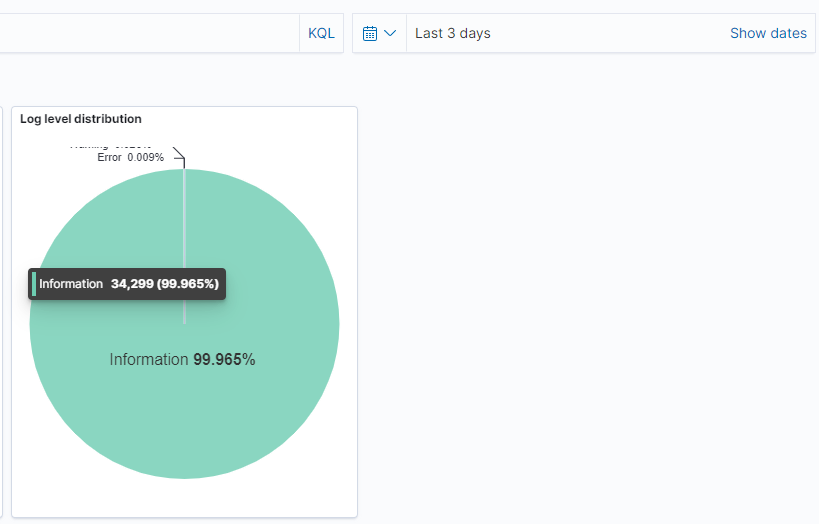
We reduced errors to just 0.009% over a 3-day period - nearly perfect reliability.
The most interesting part? We achieved all this improvement by removing code rather than adding it.
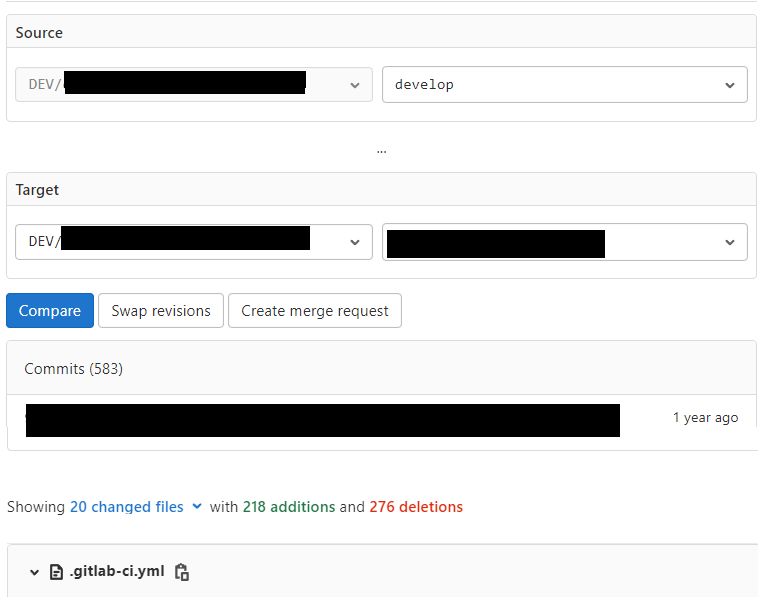
After 1 year of work, we deleted more code than we added - 276 deletions vs 218 additions. Sometimes the best solution is the simplest one.
Technology Stack Used:
- .NET for core application development
- SQL Server for data persistence
- RabbitMQ for inter service message communication
- Redis for caching
- ElasticSearch for log analysis and monitoring
- Azure DevOps for CI/CD pipelines
Conclusions
The system was successfully deployed to production and we run various performance testing. Among 100 different binary protocols, we took only 2 and we run performance testing, achieving 8.000 devices sending messages per server. Also redirected only 10 internal clients to see system behavior over time The solution effectively addressed all initial challenges while providing a scalable foundation for future expansion.
These improvements made the fleet management system more secure, scalable, and efficient. We successfully solved all the original problems and built a foundation for future growth.